Synthesizing Environment-Specific People in Photographs
Mirela Ostrek, Carol O'Sullivan, Michael J. Black, and Justus Thies
European Conference on Computer Vision (ECCV) 2024, Milano, Italy

{kind=link}
Abstract
We present ESP, a novel method for context-aware full-body generation, that enables photo-realistic synthesis and inpainting of people wearing clothing that is semantically appropriate for the scene depicted in an input photograph. ESP is conditioned on a 2D pose and contextual cues that are extracted from the photograph of the scene and integrated into the generation process, where the clothing is modeled explicitly with human parsing masks (HPM). Generated HPMs are used as tight guiding masks for inpainting, such that no changes are made to the original background. Our models are trained on a dataset containing a set of in-the-wild photographs of people covering a wide range of different environments. The method is analyzed quantitatively and qualitatively, and we show that ESP outperforms the state-of-the-art on the task of contextual full-body generation.
Method
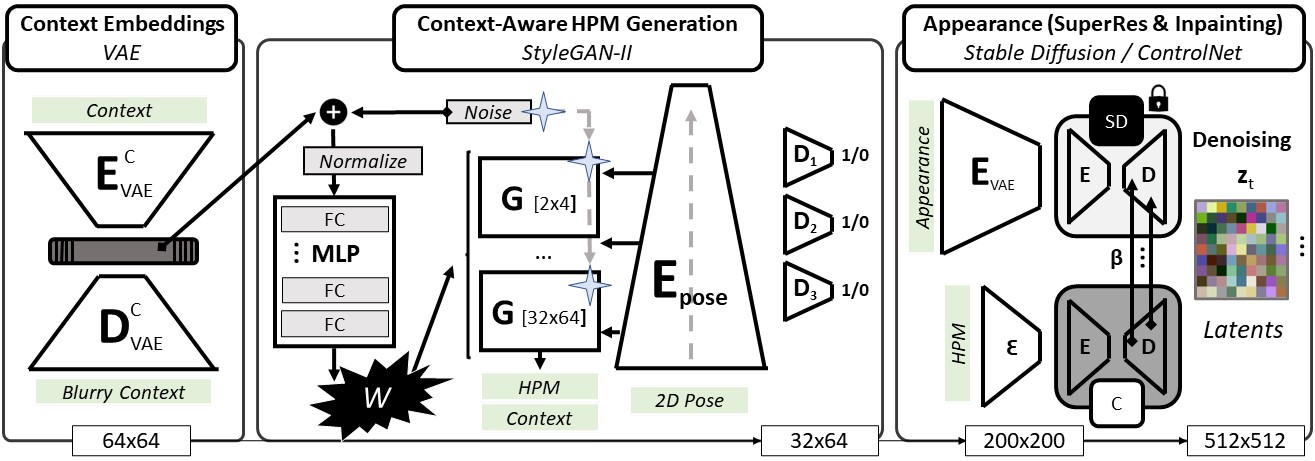
System overview: (I) an input context image is encoded into the latent space of a VAE, giving context embeddings; (II) the latter is then fed, alongside a random vector, creating a contextual style vector, into a pose-conditioned StyleGAN-II HPM generator; (III) generated HPMs are used as input for pretrained Stable Diffusion/CN modules to achieve fine-grained control over the generated clothing during inpainting.
Citing the ESP Paper and Dataset
If you find our paper or dataset useful to your research, please cite our work:
@inproceedings{ESP:ECCV:24, title = {Synthesizing Environment-Specific People in Photographs}, author = {Ostrek, Mirela and O'Sullivan, Carol and Black, Michael J. and Thies, Justus}, booktitle = {European Conference on Computer Vision (ECCV)}, month = October, year = {2024}, month_numeric = {10}}